Serverless or Not? That is the question
This post is an anecdote about about playing with cloud functions. Over the last few days I’ve been weighing the pros/cons of these services and hope my experiences might help others’ own investigations. This is about a hobby project I am working on, which is a great place to try things. There’s not much code in this post but the project is open source on GitHub.
Developer on a Dime
If you’re anything like me you probably have some combination of too many hobbies and ideas than both time and money can afford. This post primarily focuses on the money limitation and less so on time. I was interested in developing a web application with backend services while maintaining a cost of zero dollars.
Now, I’m not so cheap that I am unwilling to pay money for services. I simply want to pay a variable rate for what I use. While paying 5-10 dollars a month for an instance on some cloud service is not outrageous and has never stopped me in the past, these things add up when you have enough things you want to experiment with in isolated environments. This is a challenge for hobbyists and small business owners alike.
I will gladly pay when my web traffic or compute demands need it, but why pay for dead air?
Enter Serverless
After attending AltConf in San Jose recently, I was inspired by a talk from IBM on their Serverless Swift capabilities. Serverless, for the uninitiated, is IBM’s cloud functions service running Apache OpenWhisk. This is one of many cloud function services available from providers but the only one I know of supporting Swift code. The general idea is that instead of running entire servers in the cloud, you execute isolated blocks of code on demand and pay only for the exact amount of compute time you are using. No need to pay for idle server time. No need to load balance or scale. In principle, it sounds like a straight forward and cheap way to reliably do work in the cloud and pay per use down to the millisecond. If the amount of work to be done is relatively small, it’s free. As we can see below, 5 million executions of 500ms can cost as little as zero dollars.
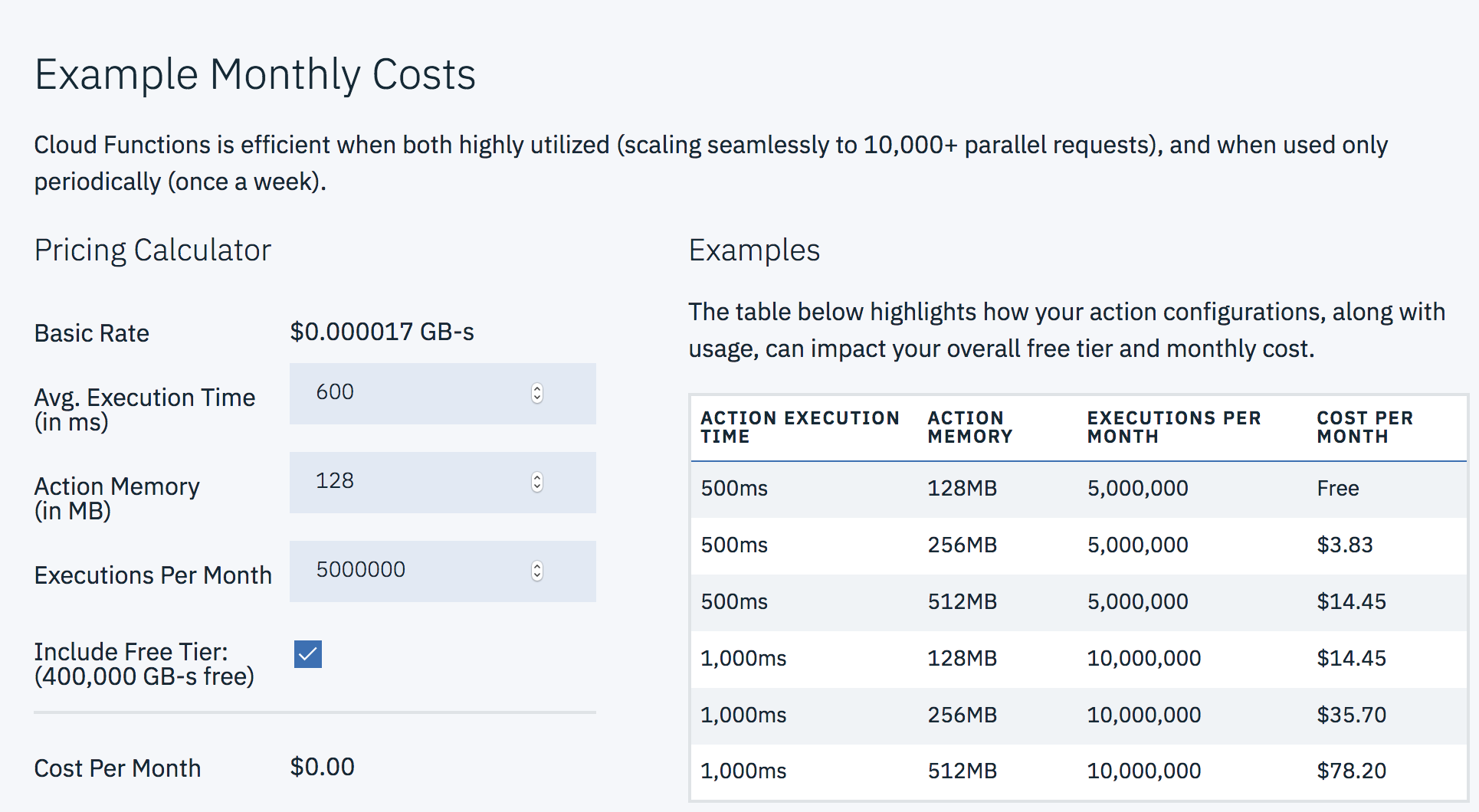
This got me thinking about how I might take advantage of some free cloud computing with Swift.
My Serverless App Concept
I decided to make a small search engine for Swift packages which I creatively named the Swift Package Directory. Visitors can search for swift packages, see popular ones, or add their own by providing the github repository name. For v1 of the website that seemed like plenty.

There are 4 main functions for this application.
- The search function that returns relevant packages from the database
- The add function that puts content in the database
- The popular function that returns packages with the most github stargazers from the database
- A long running function that updates all packages in the database. This one is doesn’t need to face externally and can run on a schedule.
The Zero Dollar Database - Cloudant
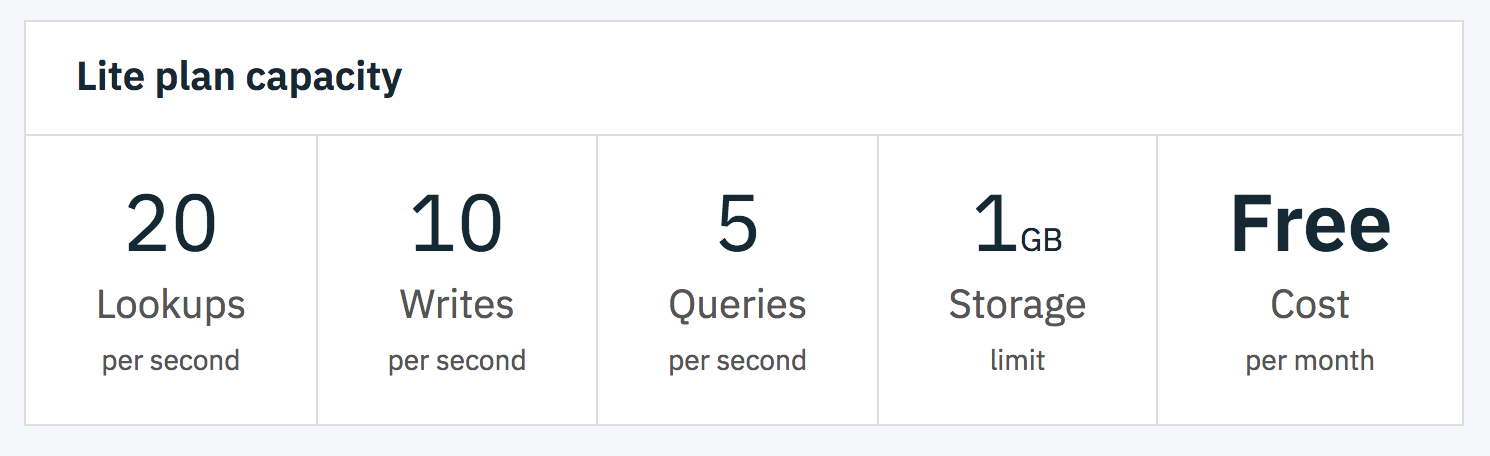 I played with a view different ideas on how to manage the database requirement of this project. Some creative ideas came to mind, like using github similarly to the way Cocoapods manages it’s repo. Ultimately I wanted to go a route that was the lowest friction and the greatest flexibility.
I played with a view different ideas on how to manage the database requirement of this project. Some creative ideas came to mind, like using github similarly to the way Cocoapods manages it’s repo. Ultimately I wanted to go a route that was the lowest friction and the greatest flexibility.
IBM Cloud offers a free tier of their Cloudant NoSQL databases, which I decided would suit my needs well enough. There was some example code from IBM available that went this route too. It’s somewhat limited on write/reads per second though so I was going to need a way to mitigate that. I’m certainly okay with paying for my real database usage, but there’s no need inflate that demand by not proactively caching resources where possible.
The Zero Dollar Website - Netlify
If I could set these four functions up in the cloud with a connected database solution, then all I would need is a static HTML website. Netlify offers a free tier for static websites that includes HTTPS and custom domains, so I decided my static assets would live there.
The Zero Dollar Cache - Cloudflare
In order to avoid aggressively demanding resources and hitting limits too quickly on Serverless or Cloudant, I expected that I would need to put a caching layer over top of this whole operation. Given this search directory would not be updated too frequently, I would put the whole website and API behind a CDN that clears regularly. Cloudflare offers a free tier with SSL support, so that kept with the plan of paying as little as possible.
Execution
You can follow along with the code I wrote here. A cloud function comes down to a main function that takes Input and a completion block. That block is called with either Output or an Error. For example, the search function’s signature looks like this:
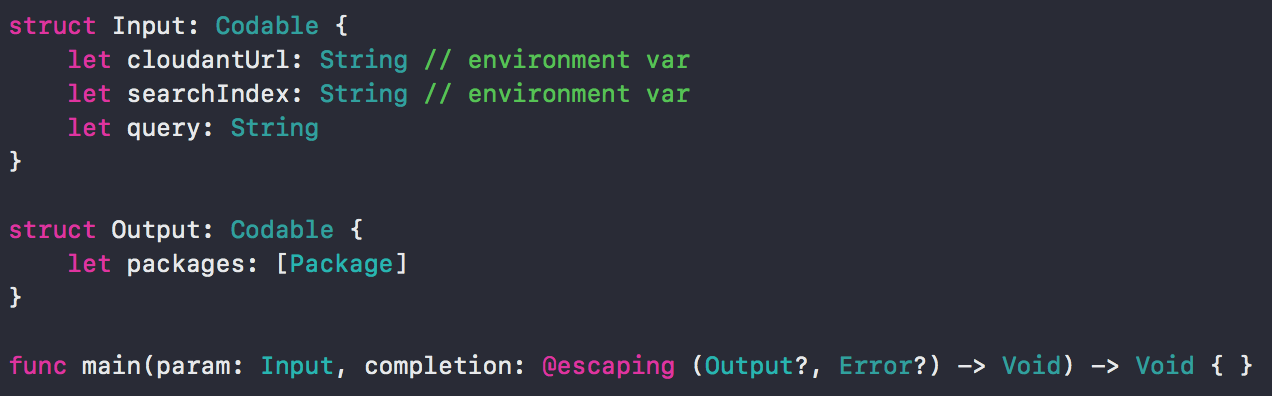
Getting running
Getting set up with Serverless and Swift was not a trivial task. IBM’s Serverless is built using OpenWhisk, which has it’s own special way of executing Swift code. I learned quickly that in order to have my code run correctly I needed to make sure it was built with an OpenWhisk Docker container that adds new functions to your Main.swift file before deploying (See that repo’s epilogue.swift & spm-build/_Whisk.swift if you want to know what gets added to your code). Some headaches ensued in learning this but on the other side it worked. My deploy.sh file was derived from IBM’s documentation on how to use this Docker container as a convenient build tool. The deploy process is not the fastest though because the container currently dumps all the build dependencies at the end of each execution. Rebuilds are from scratch.
Sharing function code
After writing out my functions it became abundantly clear there was a lot of duplicate code in each. I certainly didn’t want to suddenly have a maintenance nightmare out of four functions. That would seem like a serious step backward from writing normal server-side code. Frankly, I would pay money NOT to have to do maintenance like that.
Not to fret, however, Serverless Swift let’s you include all the packages you want, so including a ‘Core’ package with most of the code was doable. The real challenge becomes managing a folder structure. I ended up with a SPDCore Package at my root and my “actions” (i.e. serverless functions) in a actions/functionName structure. Unfortunately for Swift development, package dependencies require a tagged git commit. This meant I had to commit, tag and bump version dependencies in my actions’ Package.swift files every time I wanted to build with the latest code. I hope that in a future version of Swift Package Manager that this requirement is dropped for locally sourced dependencies.
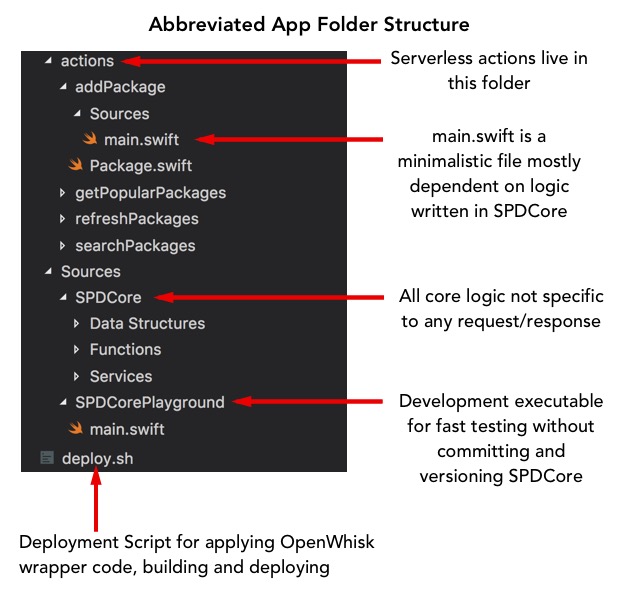
Testing locally
One thing I liked about taking the Serverless approach was that each of my functions was an executable I could test individually in XCode. It was nice to not have HTTP in the way; just inputs and outputs. Running in XCode did require me to add a little bit of MacOS only code to my Main.swift to execute the function outside of OpenWhisk, but it was very minimal. Given I was always communicating with Cloudant, I required a connection at all times, which isn’t perfect. There may have been ways for me to set up a database locally too, but it wasn’t a rabbit hole I went down on my Serverless adventure.
Running remotely
The local and remote experiences were mostly identical. I needed to input some environment variables from their management console instead of in my XCode scheme but that was about it. Testing the functions, the first response after idle time was usually a little bit cold, taking between 500ms-1000ms but things were more responsive between 50ms-70ms thereafter. This was just a measurement of the execution time, I believe, not total HTTP response time. Cloud functions may not be ideal for things that should be super fast and are prone to testing a user’s patience. With CDN caching in place I figured my function’s average response times wouldn’t be too slow though.
Going Live
Finally, I put together a static HTML site to access these serverless functions. I pushed some code to Netlify and was up and running in no time. The only thing left to bring it all together now was getting everything behind a CDN and running on HTTPS. I wanted to use my custom domain name so I had some DNS configuration to figure out. That’s when things went a little south…
Roadblock - IBM Account upgrade
I believed I would need to be managing some DNS settings through IBM, which required providing a credit card. I’ve since realized nothing I needed was in DNS but that’s hindsight. I put my information in and was denied for security reasons. After contacting customer service by phone I was asked to try again. On my second and third attempt I was denied again. IBM’s security layer requires a 1 hour waiting period between each attempt so this was starting to test my patience. Every screen change I was being re-prompted to enter a credit card now. My free services still worked, but my account was in a bad state. Exchanges continued by email, phone and Twitter over 30 hours before I was finally granted access. IBM was determined to rectify the issue after I had given up, so I give them credit.
However, in that waiting period of limited access, I naturally grew a bit frustrated. Afterall, I had just poured hours in to this new service. Suddenly I felt denied what I needed to finish my assessment. I started to feel a little foolish for taking a direction with my code that might make me too beholden to one service provider. I’ve seen the virtues of containerization before, so was this path really a good idea?
Is serverless worth it if its less transferable than a docker container? What was I losing by not taking a more traditional approach to backend? I was determined not to let myself suddenly be beholden to Serverless. What has resulted makes for a good side-by-side comparison against tranditional server setup. It also left me with a codebase ready for both.
Pivot - Wrapping the code in a Swift server
With the assumption that IBM’s Serverless may not work out, I devised a plan to serve what I had made so far while trying to make the least change possible to my serverless code. I decided to use Vapor, a server-side Swift framework. Using docker I set my project up in a container. Thanks to separating most of the core serverless code into it’s own module, my Vapor server could simply import this existing module as-is. I wrapped the logic in a few HTTP routes and it was ready to go. Better yet, Vapor was able to serve the static files itself rather than needing to worry about serving my static assets elsewhere. I stuck with using IBM’s Cloudant for the database, as my free tier IBM account was still operational and, like I said, the goal was to not touch code I had already written.
Next, I was faced with the challenge of how to deploy this code. Given that I was going to need a server running 24/7 at this point, my ambitions of a near-$0/month bill would have to be set aside, at least temporarily. I care enough about the site I’m trying to build not to let implementation/cost details keep it out of production forever.
Deploying Manually
My first thought was to try deploying the code to a cloud provider manually. I went with Digital Ocean because I knew they offer droplets for $5/month, which I can deal with. After launching an instance, I tunneled in via SSH, pulled down my git code and got it running pretty quickly. The problem with this approach, however, was all the manual work I immediately started dreading as I went through the motions.
- How am I going to deploy changes for this and then restart the server?
- How do I set up the right port access?
- How will I maximize uptime and restart if it goes down?
- How will I set up HTTPS?
All these issues and more were suddenly my burden. It was faster to set up initially, but I was unsettled about the increased responsibility. Operations related issues like these are my least favorite of software engineering problems, especially when I’m not being paid to solve them like on hobby projects.
Deploying through Heroku
I had never tried Heroku until this week but I had heard great things about the simplicity of their interface and the peace of mind it brings. So I tried packaging my site up in a docker container and deploying the code. This process was quite straight forward and, as I had hoped, it gave me peace of mind that my Digital Ocean approach lacked.
With Heroku I had to deploy the whole Docker container. This was initially 2GB of transfer and my changes, which affected the whole .build folder meant ~400MB uploads on every new deploy. I tried cutting the size down by having the project build on launch but it was too slow to start within the 60s Heroku provides.
The free instance of Heroku goes to sleep every 30 seconds and the next tier is $7/month. A little pricier but probably worth it for the luxury. If I wasn’t trying an experiment in paying as little as zero dollars, I would play with Heroku more.
Back to Serverless
After passing time fiddling with 2 alternate solutions for a day, IBM got in touch with me and helped resolve my issues. I was happy with the progress and learnings enough to want to write this post so I was determined to see a Serverless implementation through to the end.
Zero Dollar Load Testing - Loader.io
Before finally launching my website I wanted to do some load testing in order to confirm my site was ready to be resilient. Loader.io is a great little service for testing sending thousands of clients per minute at a URL and measuring average response time. They offer a free tier that lets you send clients to up to 2 unique URLs simulateously. Paid tiers let you add more clients and urls, which would be nice, but out of scope for my hobby budget. I did a few tests on Serverless with and without the CDN cache operational, as well as on Heroku for comparison.
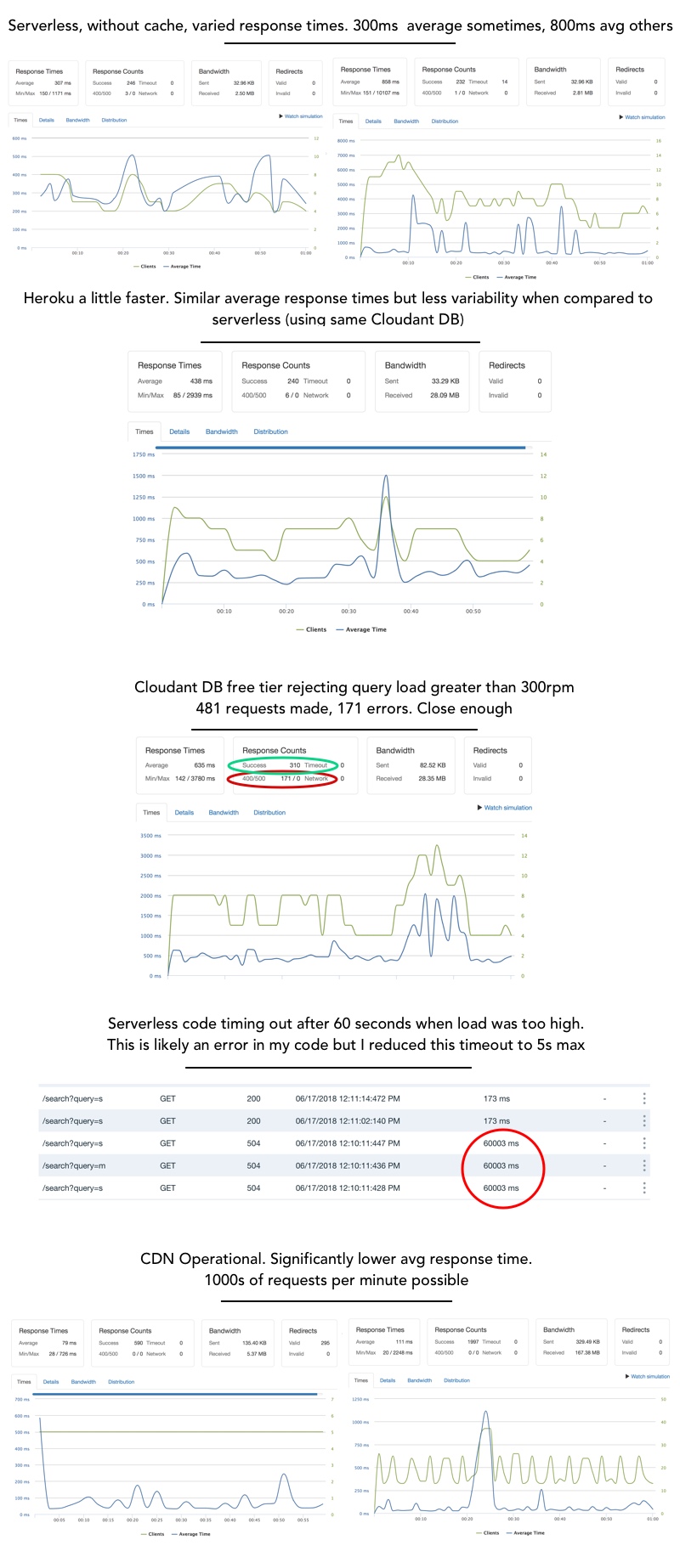
Load testing observations
- Cloudant db delivers exactly what it promises for the free tier. No more no less. For example, the 5 queries/second limit means maximum 300 requests/minute. When I sent 481 requests/minute at the server 171 requests were rejected
- Overloading was causing timeouts on functions. Running a whole 60s before getting cut off. This probably means there are some issues in my code, but I also lowered the timeout on my functions to 5 seconds because I don’t want to be paying for those 55 seconds.
- Using my CDN I could achieve 2000 requests per minute for 2 URLs.
- Response times during load testing weren’t super impressing via Serverless or Heroku. I needed to do some more investigation into this. Serverless had more variability but both reponded on average around 300-400ms.
Load reality
These tests give me a decent idea of how many requests per minute I can handle when data is not in the cache. It also demonstrates pretty effectively why a cache is necessary. In reality there’s going to be a combination of both happening. Information like the popular listings will cache quickly, since it’s on the front page. Given the wide variety of possible search terms, there will be the most uncached queries delivered for search, which is a bit concerning from a response time perspective. I’m not as worried about # of queries per second right now.
Choke points
Overall the reponse times from the uncached services is not ideal whether testing via Serverless or Heroku. This observation led me to investigate the database a little bit further. My first suspicion was that I was not using CouchDB properly. However, I did set up indices for queries and tests against the database directly performed around 20ms on average. So somewhere between the database and the service things are slowing down. It’s probably not very efficient to be connecting to the database over HTTP, interpreting it in JSON in the service then returning it again in JSON to the client. In a more traditional server setup we’d maintain a more direct connection to our database. I decided to try testing a simple ping API endpoint that does no databasing or HTTP communication at all. Just returns {success:true}.
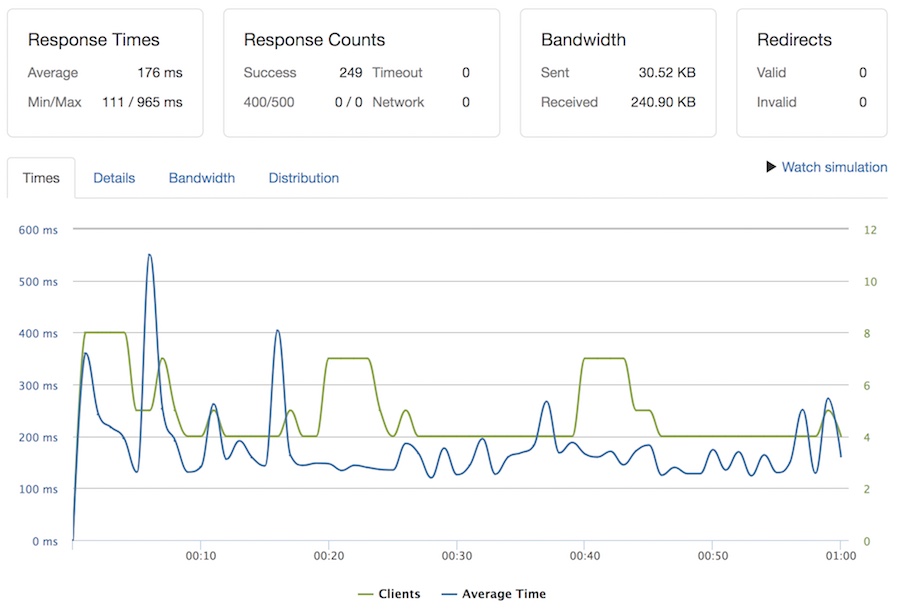
Even a simple ping is taking 180ms on average. So HTTP work with the database is not helping, but the cloud function itself is not speedy at even it’s slimmest. It even responded in over 900ms at it’s worst. The variable response times are hard to deny.
Pros & Cons
With that, I quickly want to round up some quick pros and cons about using Serverless.
Serverless Pros
- No scaling, load balancing needed
- Minimalistic approach to getting work done in the cloud
- No large deployment artifacts
- Easy to trigger any way youd like e.g. API call, git push, scheduled, another function
- Pay only for what you use. Variable costs start at $0.
Serverless Cons
- Trickier to develop offline
- Many manual tasks for things you’d do in code e.g. API Endpoint setup, Environment vars
- Once multiple functions want to share behavior or environment variables, it gets more complicated/arduous
- Frontend and backend aren’t easily developed side-by-side
- Somewhat unrealiable response times
- Still feels a lot like a server work to me.
Conclusions
For the time being I will be running Swift Package Directory off of Serverless. It’s been a fun experiment and I don’t have much to lose by sticking it out. Should this experiment grow in popularity enough to have demanding server needs I will definitely think about moving to a more traditional set up. Lucky for me, I’ve already done the leg work of designing this project to function either serverless or inside of a Docker container on a service like Heroku.
Probably one of my favorite features about Serverless right now is the triggered functions capability. I see use cases for little bits of triggered code. Some ideas boil down to a repetitive task, nothing else. Even if I migrated the API to Heroku I’d potentially keep scheduled tasks like the bulk update as cloud functions. Those seem like the best use cases. This is a new tool for our toolbelt more than a replacement to everything we know so far. Traditional HTTP APIs with demanding response times are probably not going to be the first and best use case from what I’ve seen so far.
If you have any questions or suggestions for improvement I’d love to hear them.
You can see more in the GitHub repo here
Epilogue: Features I’d like to see from Serverless
- Be able to deploy a git repo of one or more functions
Global environment variables that apply to all functions in a groupApparently this can be done with Serverless packages (subgroups) but I had trouble hooking package actions up with the API layer- Better metrics
Better HTTP error status code and response controlAvailable- Better logging features. See all printed output.